Test what moves AI visibility
Run controlled experiments on your GEO strategy. Siftly splits your tracked topics into a test group and a control group, then tracks how visibility and citation metrics diverge over time. You see which changes actually move the needle.

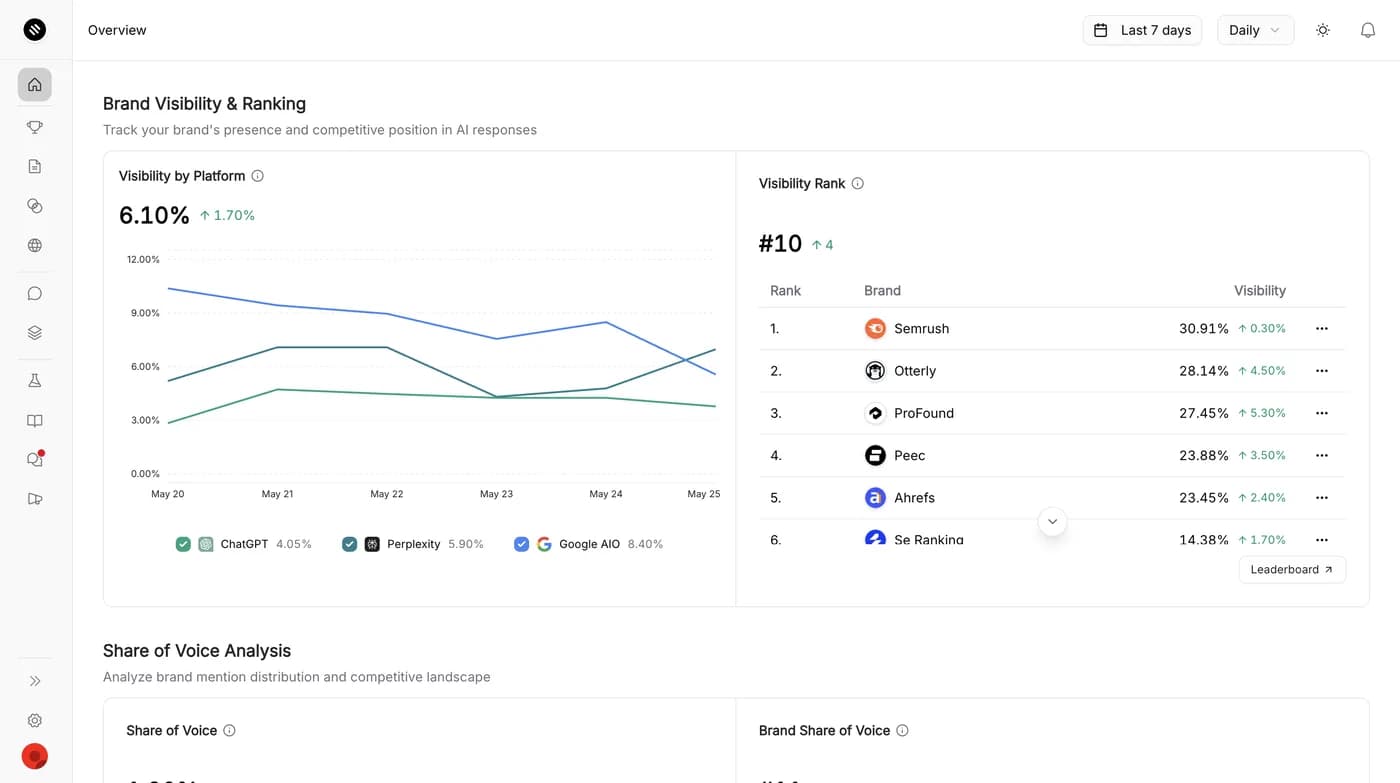
Turn GEO from guesswork into a measurable channel
Siftly splits your tracked topics into a balanced test group and control group, then tracks how visibility and citations diverge. You see which changes actually move the needle.

Divide topics into balanced groups
Siftly clusters your tracked topics by citation behavior and splits them into a test set and a control set. With balanced splits, a difference in outcome reflects your intervention, not uneven groups.
Watch the two groups diverge
Compare visibility % and citation counts for test vs control over time. A widening gap after you ship a content change is the signal that the change is working.
Scale what works, skip what doesn't
Every experiment you run becomes reusable knowledge, win or loss. Roll the winners out to new topics and retire what didn’t move the metric.
A library of every change you’ve tested
Every experiment becomes part of your team’s playbook, winners and losers alike. Reuse winning patterns across pages; retire tactics that didn’t move the needle.
You call the winner, not a black box
Siftly surfaces the raw comparison: test vs control, visibility, citations, the trend. When the gap is clear, you mark the winning variant. No opaque verdicts from a model you can’t inspect.
Why experimentation is the missing piece
AI visibility experimentation is the practice of running controlled tests: split your tracked topics into a test group and a control group, change only the test group, and compare how visibility and citation metrics move between the two over time. Without a control, any change could be noise from a model update, a competitor launch, or plain topic volatility.
Monitoring shows where you stand, not what works
Most AI visibility tools stop at monitoring. They tell you where you rank, but not what to do about it. Experimentation adds the before/after structure that turns monitoring into a system for improvement.
A control group separates signal from noise
If your AI mention rate rises 10% after a change, that means nothing on its own. Maybe the whole category moved 10%. If your test group rises 10% and control stays flat, the change did the work.
How test & control splits work
From clustering to a called winner: Siftly builds balanced groups, holds the control steady, and measures the gap your change opens up.

Cluster your topics
Siftly analyzes citation patterns across your tracked topics and uses hierarchical clustering to group similar topics together based on which sources AI engines cite for each one.
Balance the split
Topics are divided into a test set and a control set so both groups have comparable baseline visibility, citation counts, and topic coverage. Split-quality scores tell you how well-matched the two groups are before you start.
Freeze the control
Leave the content supporting your control topics unchanged. Control is your “what would have happened” baseline. It captures background movement you didn’t cause.
Ship the change on test
Implement your intervention (new content, schema additions, restructuring, freshness updates) only for pages that answer test-group topics.
Track the divergence
Siftly records visibility % and citation counts for both groups daily and renders them side-by-side, so you can see the gap grow, or not.
Call the winner
When the trend between test and control is clear and holds over a multi-week window, mark the winning variant. The experiment stays in your library for reference and reuse.
Experiment types that drive results
Different interventions move AI visibility in different ways. They also take different amounts of time to show a clear signal.
| Experiment Type | What You Change | Typical Impact | Time to Clear Signal |
|---|---|---|---|
| Data enrichment | Add original statistics, benchmarks, or survey results | High: unique data is the strongest citation driver | 2-3 weeks |
| Structural optimization | Reformat with GEO patterns (definitions, tables, ordered lists) | Medium: improves AI parseability | 2-4 weeks |
| Schema addition | Add FAQ, HowTo, Speakable, or Article schema | Medium: explicit signals for AI crawlers | 3-4 weeks |
| Content expansion | Add new sections covering subtopics competitors miss | Medium-high: improves topical authority | 3-4 weeks |
| Freshness update | Replace outdated stats with current data, update date | Medium: AI prefers fresh content | 1-2 weeks (for real-time platforms) |
| New page creation | Publish entirely new content targeting a visibility gap | Variable: depends on topic competition | 4-6 weeks |
Reading experiment results
Every experiment surfaces the same core numbers side-by-side for test vs control. The signal isn’t a single verdict. It’s a widening, directional gap that holds across a multi-week window. When the two lines clearly diverge and the gap is stable, the change worked. One experiment per cluster at a time keeps the result attributable.
Visibility %
Share of responses mentioning your brand
Citations
URLs cited from your site
Δ vs Control
Raw gap between test and control
Trend
Direction and steepness over time


Time to value, not time to configure
Go from a balanced split to a clear test-vs-control gap in weeks. Setup doesn’t take weeks.
Set up the split
Pick the topics you're testing. Siftly clusters them into balanced test and control groups using citation-based similarity so the two groups start from comparable baselines.
Ship the change
Implement your content change (new pages, schema, restructuring, freshness updates) on the pages that answer your test-group topics. Leave control-group topics untouched.
Read the gap
Watch visibility and citation metrics for test vs control diverge. When the gap is clear and stable, mark the winning variant and roll the change out to other topics.
FAQ
Your Next Customer Is Already Asking AI
See if AI recommends you — or your competitors.
Run My Free AuditExplore more features
AI Brand Monitoring
Siftly is an AI brand monitoring platform that runs your customer prompts daily across 4 major AI engines. It flags every mention, position, sentiment, hallucination, and competitor co-occurrence in one dashboard.
Open pageAI Citation Tracking
See which URLs get cited when AI platforms discuss your brand, competitors, and industry topics.
Open pageChatGPT Visibility
Siftly samples your target customer prompts across ChatGPT (GPT-4o, GPT-5, o1, ChatGPT Search) multiple times daily. It captures every mention, position, sentiment, cited source, and hallucination. Catch what single-shot checkers miss.
Open page
